Работа с DSP-ядрами
В документе приводится перечень DSP-ядер, используемых в процессорах серии «Мультикор», поясняются принципы работы с ними. Разъясняется взаимодействие CPU и DSP. Приведены примеры проектов для отладочной среды MCStudio 3M.
DSP-ядра процессоров серии «Мультикор»
DSP-ядра в составе процессоров серии «Мультикор» - разработка АО НПЦ «ЭЛВИС» и имеют обозначение ELcore-xx.
Перечень существующих ядер DSP
- ELcore-14 (в микросхеме 1892ВМ3Т),
- ELcore-24 (в микросхеме 1892ВМ2Я),
- ELcore-26 (в микросхемах 1892ВМ8Я, 1892ВМ5Я),
- ELcore-28 (в микросхеме 1892ВМ7Я),
- ELcore-30M (в микросхемах 1892ВМ10Я, 1892ВМ14Я, 1892ВМ15АФ).
- ELcore-50 (в микросхеме СКИФ).
DSP-ядра могут объединяться в кластеры. Например, ELcore-30M во всех чипах, в которых они присутствуют, объединены в кластеры DELcore-30M из двух таких ядер. Четыре ядра ELcore-28 - в кластер QELcore-28 в микросхеме 1892ВМ7Я. Ядро ELcore-26 в микросхеме 1892ВМ8Я в единственном экземпляре, а в 1892ВМ5Я их два.
Документы, рекомендуемые для ознакомления
- DSP-кластер DELcore-30M. Архитектура
- DSP-кластер DELcore-30M. Архитектура. Приложение 1. Базовая система инструкций
- DSP-кластер DELcore-30M. Архитектура. Приложение 2. Расширение системы инструкций
- Спецификация архитектурных отличий 2-ядерного DSP-кластера DELcore-30М
- DSP-ядро ELcore-30M. Перечень выявленных ограничений
- DSP-ядро ELcore-x4. Система инструкций
- DSP-ядро ELcore-26. Система инструкций
- Компилятор С/С++ Clang для DSP ELcore-30М. Руководство пользователя
- Компилятор С/С++ Clang для DSP ELcore-30M. Соглашение о вызовах
- MC Studio. Инструменты ядра DSP
- Микросхема интегральная 1892ВМ10Я. Руководство системного программиста «Прикладная библиотека»
- Компилятор C/С++ для процессора сигнальной обработки ELcore-50. Руководство программиста
- DSP-ядро Elcore50. Руководство пользователя блока VDMA
- DSP-ядро Elcore50. Руководство пользователя блока VMMU
- Elcore50. Список команд
- Техническое описание IP-блока EVENT_CTRL для DSP-ядра ELcore50
- DSP-ядро Elcore50. Руководство программиста
- Набор библиотек для DSP ELcore-50
Основные общие параметры
Общими особенностями DSP-ядер процессоров серии «Мультикор» являются гарвардская архитектура с внутренним параллелизмом по потокам обрабатываемых данных и их предназначение для вычислений и обработки информации в форматах с фиксированной и с плавающей точкой, поддержка инструкций с длинным командным словом (VLIW - Very Long Instruction Word) и возможность упаковки нескольких скалярных операций в одну команду.
Основные различия
Различия DSP-ядер представлены в сводной таблице, приведенной ниже.
Основные архитектурные характеристики DSP-ядер процессоров серии «Мультикор»
| Тип DSP | Число SIMD секций в DSP | Число фаз конвейера | Значение IDR | Память программ (PRAM) | Память данных (XRAM,YRAM) |
|---|---|---|---|---|---|
| ELcore-14 | 1 | 3 | 0x0003 | PRAM 4Kx32 | XRAM-24Kx32 YRAM-12Kx32 |
| ELcore-24 | 2 | 3 | 0x0013 | DSP0: PRAM 4Kx32 DSP1: PRAM 4Kx32 | XRAM-32Kx32 YRAM-12Kx32 |
| ELcore-26 | 2 | 4 | 0x0115 | DSP0: PRAM 4Kx32 DSP1: PRAM 4Kx32 | DSP0 XRAM-8Kx32 YRAM-8Kx32 DSP1 XRAM 8Kx32 YRAM 8Kx32 |
| ELcore-28 | 1 | 7 | 0xn309* | DSP0: PRAM 8Kx32 DSP1:PRAM 8Kx32 DSP2:PRAM 8Kx32 DSP3:PRAM 8Kx32 | DSP0 XYRAM 32Kx32 DSP1 XYRAM 32Kx32 DSP2 XYRAM 32Kx32 DSP3 XYRAM 32Kx32 |
| ELcore-30M | 1 | 7 | 0xn108* | PRAM 4Kx32 | DSP0 XYRAM32Kx32 DSP1 XYRAM 32Kx32 |
n * - номер ядра
С системой инструкций и составом программно-доступных регистров можно ознакомиться в документах, представленных ниже: («DSP-кластер DELcore-30M.Архитектура», Базовая система инструкций Расширение системы инструкций). Сравнительные значения пиковой производительности DSP-ядер приведены в таблице ниже.
Таблица 2. Сравнительная таблица пиковой производительности DSP-ядер процессоров серии
| DSP | ELcore-14 | ELcore-24 | ELcore-26 | ELcore-30M |
|---|---|---|---|---|
| Пиковая производительность по смеси арифметических операций (умножения, сложения, вычитания) | ||||
| 16-разр. фиксированная точка, оп/такт | 8 | 16 | 32 | 64 |
| 32-разр. плавающая точка, оп/такт | 3 | 6 | 12 | 16 |
| 32-разр. фиксированная точка, оп/такт | 4 | 8 | 16 | 16 |
| 8-разр. фиксированная точка, оп/такт | 18 | 36 | 82 | 96 |
| Пиковая производительность по операции МАС (умножение + накопление) | ||||
| 16-разр. фиксированная точка, оп/такт | 2 | 4 | 8 | 16 |
| 32-разр. плавающая точка, оп/такт | 1 | 2 | 4 | 4 |
| 32-разр. фиксированная точка, оп/такт | 1 | 2 | 4 | 4 |
| Пиковая производительность по операции СМАС (комплексное умножение с накоплением) | ||||
| 16-разр. фиксированная точка, оп/такт | — | — | — | 16 |
| 8-разр. фиксированная точка, оп/такт | 1 | 2 | 4 | 4 |
Взаимодействие CPU и DSP
Управление кластером DSP осуществляется CPU. DSP стартует «по команде» CPU (тогда как CPU стартует сразу по снятию сигнала Reset с микросхемы).
Для синхронизации работы DSP-ядер в кластере предусмотрено два механизма: механизм прерываний и механизм обменов через XBUF в синхронном режиме. При одновременном запросе на запись в одну и ту же ячейку буфера обмена XBUF приоритет отдается CPU.
DSP-ядра версий, созданных ранее ELcore-30M, не имели доступа к памяти за пределами XYRAM, в этом их возможности были ограничены. ELcore-30M может обращаться ко всем ресурсам процессора (внешняя и внутренняя памяти, регистры периферийных устройств). В целях совместимости адресация внутренней памяти DSP-кластера осталась без изменений.
Старт DSP-ядер
Регистр управления и состояния CSR_DSP доступен по чтению и записи и содержит биты управления кластером DSP-ядер. Запись «1» в разряд SYNSTART приводит к одновременному запуску DSP-ядер. Регистр управления и состояния DCSR содержит разряды управления, определяющие состояние и режим работы DSP-ядра, а также прерывания, формируемые DSP-ядром для обработки в RISC-ядре. Для запуска ядра необходимо записать «1» в бит «RUN» состояния исполнения программы. Пример запуска DSP-ядра см. в примере кода.
Каждое DSP-ядро может сформировать прерывание для другого ядра. Ядро, получившее прерывание, переходит в состояние «RUN», если было остановлено, и начинает исполнение подпрограммы, адрес которой хранится в специальном регистре этого ядра.
Доступ DSP-кластера к ресурсам процессора
Адресное пространство DSP находится в диапазоне адресов 0х00000000 – 0х000FFFFF при пословной адресации, которая применяется в ядрах DSP, что соответствует диапазону 0х00000000 – 0х003FFFFC при побайтовой адресации, используемой в адресном пространстве всей системы на кристалле.
Таким образом, обращаясь к адресам адресного пространства DSP (0х00000000 – 0х000FFFFF - пословная), ядро выполняет обращение к внутренней памяти кластера. В этом случае обращения в зависимости от адреса и номера DSP ядра могут направляться либо в ближний сегмент памяти данного ядра (быстрые обращения), либо в дальний сегмент памяти другого ядра (обращения через коммутатор кластера).
При обращениях к старшим адресам адресного пространства, лежащим вне адресного пространства DSP (0х000FFFFF - 0хFFFFFFFF в системе адресов DSP), обращение от DSP-ядра перенаправляется на глобальный коммутатор AXI и может быть направлено к любому адресуемому регистру или ячейке памяти, заисключением диапазона 0х00000000 – 0х003FFFFC (в системе адресов RISС-ядра). Важной особенностью внешних обращений DSP, о которой необходимо помнить программисту, является тот факт, что при переходе из адресного пространства DSP с пословной адресацией в глобальное пространство с побайтовой адресацией выполняется аппаратный сдвиг значения адресного указателя на 2 бита влево. Так, например, обращение DSP-ядра по значению A0 = 0x07F00001 приведет к обращению по физическому адресу 0x1FC00004.
DSP-кластер не имеет устройства управления памятью (MMU), поэтому работает с физическим, а не виртуальным адресом.
DSP адресует память 32-х разрядными словами, поэтому реальный физический адрес внешнего обращения получается сдвигом влево на два разряда текущего значения адресного указателя.
Примеры проектов, работающих с DSP-ядрами
Примеры ниже описывают работу с ядром ELcore-30M в составе микросхемы 1892ВМ10Я. Работа с другими ядрами и/или другими микросхемами осуществляется по схожим принципам, но имеет отличия в соответствии с особенностями архитектуры конкретного ядра и конкретной микросхемы.
Работа DSP-ядра под управлением CPU
В данной главе рассматривается пример вычисления DSP-ядром суммы д�вух величин. После выполнения вычисления DSP-ядро останавливается, устанавливается флаг в регистре запросов прерываний QSTR_DSP. В следующем фрагменте текста представлен код, выполняемый CPU-ядром.
Символы, используемые в DSP-ядре, но к которым нужен доступ из программы CPU, объявляются в коде CPU
как extern:
#include "memory_nvcom_02t.h"
// Адрес начала программы DSP-ядра
extern int Start_DSP;
// Входные параметры - числа, которые DSP складывает
extern int InA;
extern int InB;
// Результат
extern int OutC;
main()
{
int InputA=5;
int InputB=2;
int OutputC;
// обнуляем управляющие регистры ядра DSP0
DCSR(0) = 0;
Далее производятся следующие действия:
- В программный счетчик ядра DSP0 кладется адрес начала программы DSP.
- Адрес для DSP0 получается из адреса программы DSP в адресном пространстве CPU-ядра вычитанием адреса начала PRAM0 – памяти программ ядра DSP0.
- Аналогично получаются адреса переменных – только вычитанием адреса памяти данных DSP0.
- Происходит сдвиг вправо на два байта – это деление на 4, так как у DSP-ядер словная адресация, а в CPU-ядре – байтовая.
PC(0)=((unsigned int)&Start_DSP - 0xb8440000)>>2;
A0(0)=((unsigned int)&InA - 0xb8400000)>>2;
A1(0)=((unsigned int)&InB - 0xb8400000)>>2;
A2(0)=((unsigned int)&OutC- 0xb8400000)>>2;
// записываем значения входных переменных в память DSP-ядра
InA=InputA;
InB=InputB;
// Запуск ядра DSP0 на исполнение записью бита DCSR0[14]
DCSR(0) = 0x4000;
Когда ядро DSP0 закончит исполнение программы, оно выполнит инструкцию «STOP». После выполнения данной инструкции DSP-ядро останавливается и выставляет бит DCSR0[3], который транслируется в QSTR_DSP[3]. Если при этом в единице будет бит MASKR_DSP[3] будет выставлен в «1», и будут разрешены прерывания от внутренних устройств процессора, произойдет прерывание. В данном примере происходит ожидание установки бита QSTR_DSP[3].
while( !(QSTR_DSP & (1<<3)) ) ;
Результат из памяти DSP-ядра в память CPU-ядра:
OutputC=OutC;
while (1);
} ;
Далее – код на ассемблере с инструкциями, выполняемыми DSP-ядром.
.text
Метки, которые должны использоваться за пределами данного файла (в рассматриваемом случае – CPU-ядром), должны объявляться глобальными:
.global Start_DSP
.global InA
.global InB
.global OutC
Start_DSP:
В регистр R0 кладется значение по адресу, на который указывает A0 (InA)
MOVE (A0),R0.L
В регистр R2 - значение по адресу, на который указывает A1 (InB)
MOVE (A1),R2.L
Сложение:
ADDL R2.L,R0.L; результат кладем по адресу A2 (OutC)
MOVE R0.L,(A2); все
STOP .data
InA: .word 0
InB: .word 0
OutC: .word 0
.end
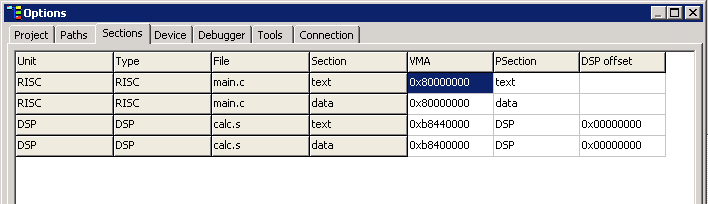
Рисунок 1 иллюстрирует размещение адресов сегментов данных и кода в данном примере.
Работа двух DSP-ядер под управлением CPU
Ниже приведен пример проекта, который демонстрирует взаимодействие между CPU и двумя DSP-ядрами. CPU передает ядрам DSP0 и DSP1 по два числа, которые складываются друг с другом средствами DSP-ядер. Результат сохраняется в переменные DSP0_OutputC и DSP1_OutputC соответственно. Алгоритм проекта следующий:
- Задаются значения входных переменных.
- Настраиваются регистры DSP0 и DSP1.
- В регистр PC ядра DSP0 заносится адрес функции, производящей вычисление (DSP0_calculate()).
- Аналогично для DSP1.
- Запуск DSP0, запуск DSP1.
- По очереди ожидается событие останова DSP ядер.
- Передача вычисленных значений в переменные, расположенные в области памяти CPU-ядра.
Код для CPU:
/*********************************************************************
* CPU_DSP0_DSP1
* Демонстрирует взаимодействие между CPU- и DSP-ядрами
* Передает ядру DSP0 и DSP1 два числа, которые складываются
* средствами DSP-ядер. Результат сохраняется в переменные
* DSP0_OutputC и DSP1_OutputC соответственно
**********************************************************************/
#include "memory_nvcom_02t.h"
extern unsigned int DSP0_In_A;
extern unsigned int DSP0_In_B;
extern unsigned int DSP0_Out_C;
extern unsigned int DSP0_calculate;
extern unsigned int DSP1_In_A;
extern unsigned int DSP1_In_B;
extern unsigned int DSP1_Out_C;
extern unsigned int DSP1_calculate;
int main() {
unsigned int DSP0_InputA = 5;
unsigned int DSP0_InputB = 2;
unsigned int DSP0_OutputC;
unsigned int DSP1_InputA = 6;
unsigned int DSP1_InputB = 3;
unsigned int DSP1_OutputC;
DSP0_In_A = DSP0_InputA;
DSP0_In_B = DSP0_InputB;
DSP1_In_A = DSP1_InputA;
DSP1_In_B = DSP1_InputB;
// настройка регистров DSP0
DCSR(0) = 0;
SR(0) = 0;
// настройка регистров DSP1
DCSR(1) = 0;
SR(1) = 0;
// занесение в регистр PC ядра DSP0 адреса функции DSP0_calculate()
// память PRAM ядра DSP0 в адресном пространстве CPU-ядра начинается с // адреса 0xb844_0000
PC(0) = ((unsigned int) &DSP0_calculate - 0xb8440000) >> 2;
// занесение в регистр PC ядра DSP1 адреса функции DSP1_calculate()
// память PRAM ядра DSP1 в адресном пространстве CPU-ядра начинается с // адреса 0xb884_0000
// &DSP1_calculate - адрес функции в адресном пространстве CPU-ядра
// делим адрес на 4 (сдвиг на 2 бита вправо)
PC(1) = ((unsigned int) &DSP1_calculate - 0xb8840000) >> 2;
// запуск DSP0
DCSR(0) = 0x4000;
// запуск DSP1
DCSR(1) = 0x4000;
// Разряд QSTR_DSP[3] устанавливается в «1», если DSP0 выполнило STOP
while ((QSTR_DSP & 0x8)==0);
DSP0_OutputC = DSP0_Out_C;
// Разряд QSTR_DSP[11] устанавливается в «1», если DSP1 выполнило STOP
while ((QSTR_DSP & 0x800)==0);
DSP1_OutputC = DSP1_Out_C;
while (1);
return 0;
}
Далее – код на ассемблере с инструкциями, выполняемыми DSP-ядром DSP0:
.global DSP0_calculate
.global DSP0_In_A
.global DSP0_In_B
.global DSP0_Out_C
.text
DSP0_calculate:
MOVE DSP0_In_A,A0.S
MOVE DSP0_In_B,A1.S
MOVE DSP0_Out_C,A2.S
MOVE (A0),R0.L
MOVE (A1),R2.L
ADD R0,R2,R0
MOVE R0.L,(A2)
STOP
nop
nop
.data
DSP0_In_A: .word 0
DSP0_In_B: .word 0
DSP0_Out_C: .word 0
Далее – код на ассемблере с инструкциями, выполняемыми DSP-ядром DSP1:
.global DSP1_calculate
.global DSP1_In_A
.global DSP1_In_B
.global DSP1_Out_C
.text
DSP1_calculate:
MOVE DSP1_In_A,A0.S
MOVE DSP1_In_B,A1.S
MOVE DSP1_Out_C,A2.S
MOVE (A0),R0.L
MOVE (A1),R2.L
ADD R0,R2,R0
MOVE R0.L,(A2)
STOP
nop
nop
.data
DSP1_In_A: .word 0
DSP1_In_B: .word 0
DSP1_Out_C: .word 0
В кластере DELcore-30M память XYRAM для обеих DSP-ядер – общая. То есть, если производить запись или чтение по одинаковому адресу из DSP0 и DSP1, то произойдет обращение к одной и той же ячейке памяти. Поэтому в настройках проекта («Options → Section») добавлено поле «Offset» для смещения секций данных для разных ядер.
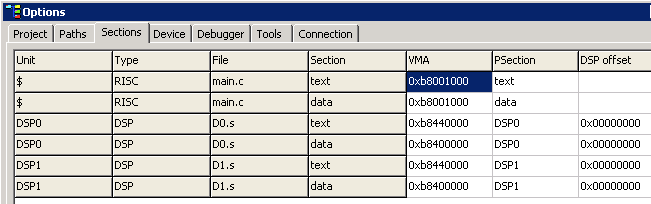
Приведённый ниже рисунок иллюстрирует, по каким адресам в данном случае располагаются переменные (DSP0_In_A, DSP0_In_B, DSP0_Out_C, DSP1_In_A, DSP1_In_B,DSP1_Out_C).
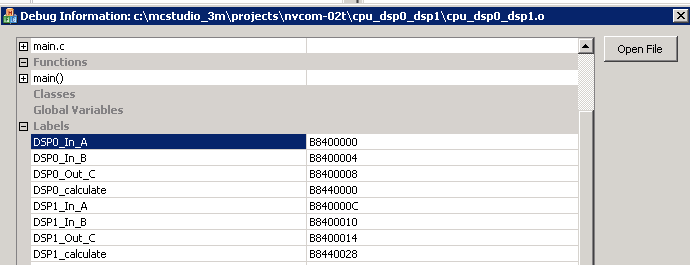
Поскольку в данном случае поле DSP offset не используется, все переменные находятся в ближней для DSP0 области XYRAM. Для того чтобы расположить переменные DSP1_In_A, DSP1_In_B, DSP1_Out_C в области XYRAM ближней к DSP1 необходимо задать для них смеще�ние 0x8000.
Демонстрация инструкций VLIW
VLIW (англ. very long instruction word — «очень длинная машинная команда»). Характеризуется тем, что одна инструкция процессора содержит несколько операций, которые должны выполняться параллельно. Параллельное выполнение инструкций возможно за счёт параллельного использования двух операционных устройств и двух коммутаторов данных. Длинная команда на входе процессора разделяется на 4 коротких. Каждая из 4 коротких команд предназначена для конкретного блока.
Вычислительные команды выполняются двумя операционными блоками OP1, OP2. Блоки OP1 и OP2 имеют различный набор вычислительных элементов. Некоторые инструкции могут быть выполнены только блоком OP1, некоторые только OP2. Часть инструкций может быть выполнена, как блоком OP1, так и блоком OP2. Возможность исполнения команды конкретным операционным блоком следует уточнить в документе Пр�иложение 1. Базовая система инструкций.
При использовании двух команд пересылки, одна из команд должна выполнять пересылку данных из адреса, записанного в регистре Ax в регистр общего назначения, а другая из адреса, записанного в регистр AT в регистр R0.
Вычислительные инструкции могут быть выполнены параллельно если:
- Результат одной не зависит от результата другой;
- В длинной инструкции отсутствуют две инструкции которые могут быть выполнены только на одном операционном устройстве.
Приведенные ниже примеры кода демонстрируют лишь саму суть VLIW-инструкций, с точки зрения осмысленности приведенные сочетания операций оценивать не надо.
Две вычислительные инструкции
В этом разделе приведен пример параллельного выполнения DSP-ядром инструкций умножения и выбора наибольшего значения.
.text
.global Start_DSP
.global InA
.global InB
.global OutC
.global OutD
Start_DSP:
;в регистр R0 кладется значение по адресу, на который указывает A0 ;(InA),5
MOVE (A0),R0.L
; в регистр R2 - значение по адресу, на который указывает A1 (InB), 2
MOVE (A1),R2.L
; регистр R8 обнуление
MOVE 0,R8.L
; параллельно умножение и выбор наибольшего значения
MPUU R0,R2,R0.L MAX R0,R2,R8
; результат поиска максимума кладется по адресу A2 (OutC)
MOVE R8.L,(A2)
; результат поиска произведения кладется по адресу A3 (OutD)
MOVE R0.L,(A3)
Далее в коде выполняется переход DSP-ядра в состояние останова:
STOP
.data
InA: .word 0
InB: .word 0
OutC: .word 0
OutD: .word 0
.end
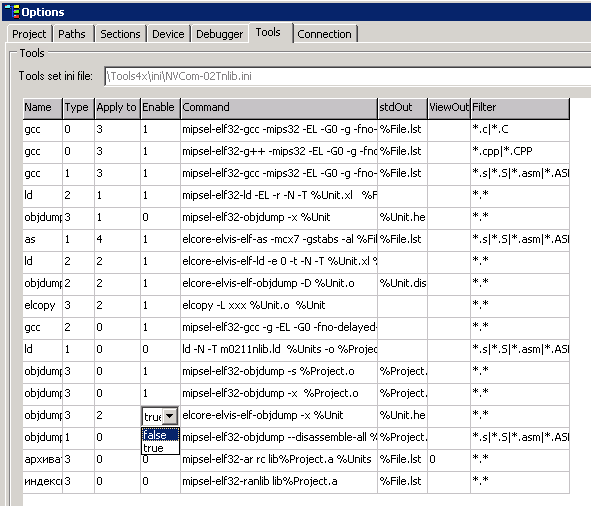
При сборке DSP-проекта, созданного с настройками по умолчанию, компилятор выдает следующее предупреждение:

Для того чтобы оно не возникало, нужно отключить команду elcore-elvis-elf-objdump -x %Unit, как показано на Рисунке 5.
Для того чтобы убедиться в параллельном исполнении инструкций, нужно после запуска отладчика открыть окно «Locals Variables», содержащее значения переменных проекта (InA, InB, OutC, OutD) и убедиться, что максимальное значение, выбранное из переменных InA и InB, не поменялось после их перемножения:

Две вычислительные инструкции и одна инструкция пересылки
Здесь показан пример VLIW_2COUNT_MOVE, иллюстрирующий параллельное исполнение двух вычислительных инструкций и одной инструкции пересылки. CPU- программа:
#include "memory_nvcom_02t.h"
// Адрес начала программы DSP-ядра
extern int Start_DSP;
Входные параметры - числа, которые DSP перемножает, параллельно находит максимальное из них и третье, над которым выполняется пересылка:
extern int InA;
extern int InB;
extern int InC;
// результат
extern int OutD;
extern int OutE;
extern int OutF;
main()
{
int InputA=5;
int InputB=2;
int InputC=3;
int OutputD;
int OutputE;
int OutputF;
// обнуление управляющих регистров ядра DSP0
DCSR(0) = 0;
SR(0) = 0;
PC(0)=((unsigned int)&Start_DSP - 0xb8440000)>>2
A0(0)=((unsigned int)&InA - 0xb8400000)>>2
A1(0)=((unsigned int)&InB - 0xb8400000)>>2
A4(0)=((unsigned int)&InC- 0xb8400000)>>2
A2(0)=((unsigned int)&OutD- 0xb8400000)>>2
A3(0)=((unsigned int)&OutE- 0xb8400000)>>2
A5(0)=((unsigned int)&OutF- 0xb8400000)>>2
// запись значениq входных переменных в память DSP-ядра
InA=InputA;
InB=InputB;
InC=InputC;
// Запуск ядра DSP0 на исполнение записью бита DCSR0[14]
DCSR(0) = 0x4000;
Когда ядро DSP0 закончит программу - оно выполнит инструкцию STOP, после выполнения данной инструкции DSP-ядро останавливается и выставляет бит QSTR_DSP[3].
while( !(QSTR_DSP & (1<<3)) ) ;
// выбор результата из памяти DSP-ядра в память CPU-ядра
OutputD=OutD;
OutputE=OutE;
OutputF=OutF;
while (1) ;
};
DSP-код:
.text
.global Start_DSP
.global InA
.global InB
.global InC
.global OutD
.global OutE
.global OutF
Start_DSP:
; в регистр R0 кладется значение по адресу, на который указывает A0 ;(InA), 5
MOVE (A0),R0.L
; в регистр R2 - значение по адресу, на который указывает A1 (InB), 2
MOVE (A1),R2.L
; в регистр R4 - значение по адресу, на который указывает A4 (InC), 3
MOVE (A4),R4.L
; регистр R8 обнуляем
MOVE 0,R8.L
; регистр R9 обнуляем
MOVE 0,R6.L
Выполняются параллельно инструкции умножения MPUU, выбора максимального значения MAX и инструкция пересылки:
MPUU R0,R2,R0.L MAX R0,R2,R8 MOVE R4,R6.L
Результат поиска максимума кладется по адресу A2 (OutD)
MOVE R8.L,(A2)
Результат поиска произведения кладется по адресу A3 (OutE)
MOVE R0.L,(A3)
Результат пересылки кладется по адресу A5 (OutF)
MOVE R6.L,(A5)
Выполняется переход DSP-ядра в состояние останова:
STOP
.data
InA: .word 0
InB: .word 0
InC: .word 0
OutD: .word 0
OutE: .word 0
OutF: .word 0
.end
В параллельном выполнении инструкций убедиться можно как показано в примере выше, см. главу 0.
Здесь рассматривается пример параллельного исполнения четырех инструкций: двух вычислительных и двух пересы�лок (VLIW_2COUNT_MOVE). Программа CPU-ядра:
* Демонстрирует работу с DSP-ядром. *
* Параллельное исполнение *
* двух вычислительных инструкций и двух инструкций пересылки. *
* *
* У процессора NVCom-02T два DSP-ядра, работа с ними идентична. *
* В настоящем примере выполняется работа с ядром DSP0. *
* CPU-ядро управляет DSP-ядром. *
* Для того чтобы убедиться в параллельном исполнении инструций, *
* в окне Local Variables выводим значение переменных *
* OutD, OutE, OutF OutJ и видим, *
* что максимальное значение, выбранное из переменных InA и InB *
* не поменялось после их перемножения и произошли две пересылки.*
* Вторая пересылка- считывание слова 0x12345678 из XYRAM *
* по адресу 0x321. *
* *
****************************************************************/
#include "memory_nvcom_02t.h"
// Адрес на�чала программы DSP-ядра
extern int Start_DSP;
// входные параметры - числа, которые DSP перемножает и
// параллельно находит максимальное из них
extern int InA;
extern int InB;
// результат
extern int OutD;
extern int OutE;
extern int OutF;
extern int OutJ;
main()
{
int InputA=5;
int InputB=2;
int OutputD;
int OutputE;
int OutputF;
int OutputJ;
// обнуляем управляющие регистры ядра DSP0
DCSR(0) = 0;
SR(0) = 0;
// в программный счетчик ядра DSP0 кладем адрес начала программы DSP
// адрес для DSP0 получаем из адреса программы DSP в адресном пространстве
// CPU-ядра, вычитая адрес начала PRAM0 - памяти программ ядра DSP0.
// Аналогично получаем адреса переменных - только вычитаем адрес
// памяти данных DSP0.
// сдвиг вправо на два байта == деление на 4 - так как у DSP-ядер
// словная адресация, а в CPU-ядре - байтовая.
PC(0)=((unsigned int)&Start_DSP - 0xb8440000)>>2;//(unsigned int)&PRAM)>>2;
A0(0)=((unsigned int)&InA - 0xb8400000)>>2;//(unsigned int)&XRAM)>>2;
A1(0)=((unsigned int)&InB - 0xb8400000)>>2;//(unsigned int)&XRAM)>>2;
A2(0)=((unsigned int)&OutD- 0xb8400000)>>2;//(unsigned int)&XRAM)>>2;
A3(0)=((unsigned int)&OutE- 0xb8400000)>>2;//(unsigned int)&XRAM)>>2;
A4(0)=((unsigned int)&OutF- 0xb8400000)>>2;//(unsigned int)&XRAM)>>2;
A6(0)=((unsigned int)&OutJ- 0xb8400000)>>2;//(unsigned int)&XRAM)>>2;
// записываем значения входных переменных в память DSP-ядра
InA=InputA;
InB=InputB;
// Запускаем ядро DSP0 на и�сполнение записью бита DCSR0[14]
DCSR(0) = 0x4000;
// Когда ядро DSP0 закончит программу - оно выполнит инструкцию STOP,
// заботливо оставленную нами в программе для DSP-ядра.
// После выполнения данной инструкции DSP-ядро останавливается и
// выставляет 3бит QSTR_DSP[3]. Опрос.
while( !(QSTR_DSP & (1<<3)) ) ;
// забираем результат из памяти DSP-ядра в память CPU-ядра
OutputD=OutD;
OutputE=OutE;
OutputF=OutF;
OutputJ=OutJ;
// Все
while (1) ;
};
Код для DSP-ядра:
.text
.global Start_DSP
.global InA
.global InB
.global OutD
.global OutE
.global OutF
.global OutJ
Start_DSP:
MOVE 0,R0.L
MOVE 0,R2.L
MOVE 0,R6.L
MOVE 0,R8.L
MOVE 0,R10.L
; в регистр R0 кладется значение по адресу, на который указывает A0 ;(InA), 5
MOVE (A0),R6.L
; в регистр R2 - значение по адресу, на который указывает A1 (InB), 2
MOVE (A1),R2.L
; для демонстрации надо считать слово 0x12345678 из XYRAM по адресу ;0x321.
; Запись слова 0x12345678 по адресу 0x321:
MOVE 0x321, R12.L
MOVE R12.L, A7
MOVE 0x12345678, R14.L
MOVE R14.L, (A7)
; начало чтения: чтение адреса 0x321 в регистр AT
MOVE R12.L, AT
; параллельно происходит умножение, выбора наибольшего и выполняются ;2 пересылки:
MPUU R6,R2,R6.L MAX R6,R2,R8 MOVE R6.L,R10.L MOVE (AT), R0.L
; результат поиска максимума кладется по адресу A2 (OutD)
MOVE R8.L,(A2)
; результат поиска произведения кладется по адресу A3 (OutE)
MOVE R6.L,(A3)
; результат пересылки кладеnтся по адресу A4 (OutF)
MOVE R10.L,(A4)
; результат пересылки кладется по адресу A6 (OutJ)
MOVE R0.L, (A6)
; выполняется переход DSP-ядра в состояние останова
STOP
.data
InA: .word 0
InB: .word 0
OutD: .word 0
OutE: .word 0
OutF: .word 0
OutJ: .word 0
.end
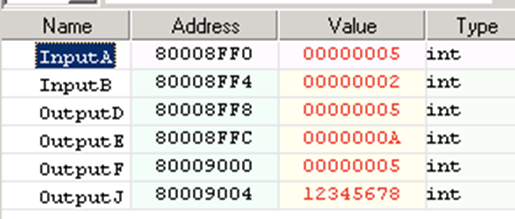
Для того чтобы убедиться в параллельном исполнении инструкций, в окне «Locals Variables» необходимо вывести значения переменных OutputD, OutputE, OutputF и OutputJ и убедиться, что максимальное значение (OutE), выбранное из переменных InA и InB не поменялось после их перемнож�ения (OutD), и произошло две пересылки:
- по адресу A4 (OutF) лежит значение регистра, на который указывает рагистр A0 (5);
- значение, прочитанное по регистру AT (OutJ) совпадает с тем, что было занесено.
Вкладка Locals Variables с результатом выполнения примера VLIW_2COUNT_2MOVE приведена на рисунке ниже.
Демонстрация доступа DSP к внешней памяти
Как было сказано выше, возможности ядра ELcore-30M расширены по сравнению с предыдущими версиями, и DSP может обращаться, в том числе, к внешней памяти. В приведенном ниже примере MFBSP_GPIO_DSP, DSP, обращаясь к регистрам периферийного порта MFBSP, переключает выводы LDAT[5:4] на выход и инвертирует значения на выводах. В результате диоды на плате NVCom-02TEM-3U мигают попеременно с интервалом в 1 секунду.
Код CPU-ядра (управляет DSP-ядром):
#include "memory_nvcom_02t.h"
// Адрес начала программы DSP-ядра
extern int Start_DSP;
main()
{
// обнуляем управляющие регистры �ядра DSP0
DCSR(0) = 0;
SR(0) = 0;
- В программный счетчик ядра DSP0 помещается адрес начала программы DSP.
- Адрес для DSP0 получается из адреса программы DSP в адресном пространстве CPU-ядра вычитанием адреса начала PRAM0 - памяти программ ядра DSP0.
- Значения A1 и A2 физических адресов переменных получаются вычитанием 0xA0000000.
- При вычислении адресов производится сдвиг вправо на два байта, что соответствует делению на 4, так как у DSP-ядер словная адресация, а в CPU-ядре - байтовая.
PC(0)=((unsigned int)&Start_DSP - 0xb8440000)>>2
A1(0)=((unsigned int)&DIR_MFBSP1- 0xa0000000)>>2;
A2(0)=((unsigned int)&GPIO_DR1- 0xa0000000)>>2;
//Запуск ядра DSP0 на исполнение записью бита DCSR0[14]:
DCSR(0) = 0x4000;
while (1) ;
};
Код DSP-ядра:
.text
.global Start_DSP
.global invert_diods_ligths
; Программа для DSP-ядра
Start_DSP:
; переключаем выводы LDAT[5:4] в режим выхода DIR_MFBSP1(0xB82F7108) ;= 0xC0;
MOVE 0xC0,R0.L
MOVE R0.L,(A1)
; устанавливаем противоположные значения разрядов
; GPIO_DR1[7] и GPIO_DR1[6] GPIO_DR1(B82F710C) = 0x80
MOVE 0x80,R2.L
MOVE R2.L,(A2)
; бесконечный цикл
invert_diods_ligths:
; в бесконечном цикле инвертируем биты GPIO_DR1[7:6], ждем 1 секунду
; инвертируем биты GPIO_DR1[7:6]:
NOP
EOR 0xC0,R2
MOVE R2.L,(A2)
; при частоте DSP 240 MГц для задержки в 1 необходимо
; примерно 140 млн тактов:
DO 10000,label2
DO 14000,label1
NOP
label1:
NOP
label2:
NOP
J invert_diods_ligths
.data
.end
Компилятор Си для DSP
В настоящем разделе представлены примеры, написанные с использованием компилятора Си для DSP. Перечисленые проекты находятся в составе среды MCStudio3M в папке %MCS3M%/SamplesClang/NVCom-02T.
Пример вычислений (#sample-calculate)
Код для DSP-ядра приведен ниже:
int main()
{
int a, b,c;
a = 10;
b = 20;
c = a - b;
return c;
}
В данном примере загрузка программы в DSP выполняется функцией benchmark.
#include <unistd.h>
#include "risc_runtime/nvcom_01.h"
#include "risc_runtime/debug_printf.h"
#include "risc_runtime/simple_time.h"
#include "risc_runtime/overlay.h"
#include "risc_runtime/init.h"
extern int __dsp_main;
//
// @name: benchmark
// @description: prepare dsp core run it
// @input int i - parameter for send to dsp function
// @output - value, returned by dsp function
//
int benchmark(int i)
{
// setup initial values for dsp registers from overlay descriptions
int DSP_PC = (unsigned int)&__dsp_main;
struct ovl_ctx *ctx = find_overlay_ctx(DSP_PC);
int DSP_NUM = ctx->dsp_info->num;
int QSTR_STOP = ctx->dsp_info->qstr_stop;
// load program into dsp memory
if(!load_overlay(ctx)) return 0;
// setup dsp registers
DCSR(DSP_NUM) = 0;
SR(DSP_NUM) = 0;
SS(DSP_NUM) = (*ctx).__exit_dsp;
SP(DSP_NUM) = 1;
PC(DSP_NUM)=(DSP_PC - (unsigned int)((*ctx).__text_src) + ((*ctx).__text_offset))>>2;
A7(DSP_NUM)=0x7ffc;
A6(DSP_NUM)=0x7ffc;
// it has no sense in this example, you can send parameter to dsp function via register
// see "calling convention" in clang documentation
R0_L(DSP_NUM) = i;
R1_L(DSP_NUM) = 0;
DCSR(DSP_NUM) = 0x4000;
// run dsp
const unsigned qstr_mask = (0xf << (DSP_NUM * 8));
const unsigned stop_mask = (1<<QSTR_STOP);
while(1)
{
unsigned qstr = QSTR_DSP;
if((qstr & qstr_mask) == stop_mask) break;
}
// receive value from dsp
// see "calling convention" in clang documentation
return R0_L(DSP_NUM);
}
main()
{
config_overlay(0,0);
int dsp_ret = benchmark(0);
while (1) ;
};
Пример вызова специфических функций DSP (sample_builtins)
Компилятор поддерживает набор встроенных функций, которые соответствуют системе инструкций ELcore. Использование builtin-функций по функциональности аналогично использованию ассемблерных вставок, но в некоторых вариантах использование более компактно и понятно для программиста. Builtin-функции необходимо использовать при оптимизации кода, когда существующие стандартные механизмы оптимизации (использование опции –O3, автовекторизации и VLIW-пакетов) не дают необходимой скорости вычисления.
В примере производится вычисление значения функции a *x + y, где x и y – одномерные массивы
размера 4, a-константа. Вычисление производится двумя способами – прямое вычисление a* x + y и с
спользованием builtin функций.
В приведенном примере используются builtin функции:
_builtin_cv4f32_mul(k,x1[i])– четыре умножения на общую константу, соответствующая инструкция DSP — FM4C;_builtin_v4f32_add(mul,y1[i])– четыре сложения float, соответствующая инструкция DSP – FA4.
Код для DSP:
typedef __attribute__((__vector_size__(4 *sizeof(float)))) float _v4f32;
float x[200] __attribute__((aligned(16)));
float y[200] __attribute__((aligned(16)));
float z0[200] __attribute__((aligned(16)));
float z1[200] __attribute__((aligned(16)));
//
// @description: initialize input vectors with some values
//
void SetupVectors(float *in1, float* in2, int length)
{
int i, j;
for (i = 0; i < length; i++)
{
in1[i]= i * 2.3 + 1;
}
for (j = length; j >= 0; j--)
{
in2[j]= (length-j) * 1.6;
}
}
//
// @description: calculate const*vector1+vector2
//
void Func0(float *in1, float* in2, float k, float* out, int length)
{
for (int i = 0; i < length; i++)
{
out[i]= k * in1[i] + in2[i];
}
}
//
// @description: calculate const*vector1+vector2 by using elcore builtin
// functions
//
void Func1(float *in1, float* in2, float k, float* out, int length)
{
_v4f32 *x1 = (_v4f32*)in1;
_v4f32 *y1 = (_v4f32*)in2;
_v4f32 *z1 = (_v4f32*)out;
for (int i = 0; i < length/4; i++)
{
_v4f32 mul =__builtin_cv4f32_mul(k, x1[i]);
z1[i] =__builtin_v4f32_add(mul, y1[i]);
}
}
int main()
{
SetupVectors(x, y, 200);
Func0(x, y, 4.0f, z0, 200);
Func1(x, y, 4.0f, z1, 200);
return 0;
}
Код для CPU:
#include <unistd.h>
#include "risc_runtime/nvcom_01.h"
#include "risc_runtime/debug_printf.h"
#include "risc_runtime/simple_time.h"
#include "risc_runtime/overlay.h"
#include "risc_runtime/init.h"
extern int __dsp_main;
//
// @name: benchmark
// @description: prepare dsp core run it
// @input int i - parameter for send to dsp function
// @output - value, returned by dsp function
//
int benchmark(int i)
{
// setup initial values for dsp registers from overlay descriptions
int DSP_PC = (unsigned int)&__dsp_main;
struct ovl_ctx *ctx = find_overlay_ctx(DSP_PC);
int DSP_NUM = ctx->dsp_info->num;
int QSTR_STOP = ctx->dsp_info->qstr_stop;
// load program into dsp memory
if(!load_overlay(ctx)) return 0;
// setup dsp registers
DCSR(DSP_NUM) = 0;
SR(DSP_NUM) = 0;
SS(DSP_NUM) = (*ctx).__exit_dsp;
SP(DSP_NUM) = 1;
PC(DSP_NUM)=(DSP_PC - (unsigned int)((*ctx).__text_src) + ((*ctx).__text_offset))>>2;
A7(DSP_NUM)=0x7ffc;
A6(DSP_NUM)=0x7ffc;
// it has no sense in this example, you can send parameter to dsp function via register
// see "calling convention" in clang documentation
R0_L(DSP_NUM) = i;
R1_L(DSP_NUM) = 0;
DCSR(DSP_NUM) = 0x4000;
// run dsp
const unsigned qstr_mask = (0xf << (DSP_NUM * 8));
const unsigned stop_mask = (1<<QSTR_STOP);
while(1)
{
unsigned qstr = QSTR_DSP;
if((qstr & qstr_mask) == stop_mask) break;
}
// receive value from dsp
// see "calling convention" in clang documentation
return R0_L(DSP_NUM);
}
main()
{
config_overlay(0,0);
int dsp_ret = benchmark(0);
while (1) ;
};
Реализация медианного фильтра (sample_median)
В приведенном примере показан алгоритм фильтрации сигнала одномерным медианным фильтром:
- Входящий сигнал signal подается на медианный фильтр (MedianFilter).
- Выбираются значения входн�ого сигнала, попавшие в окно фильтра.
- Происходит сортировка значений сигнала, попавшего в окно.
- Выбор из медианного значения и запись его в медианный образ сигнала.
- Действия 2-4 повторяются для каждой точки входящего сигнала.
Код для DSP:
float x[200];
float y[200];
float z0[200];
float z1[200];
// @description: 1d median filter
// @parameters : signal - input signal
// result - output signal
// N - length of the signal
void MedianFilter(const float* signal, float* result, int N)
{
// Move window through all elements of the signal
for (int i = 2; i < N - 2; ++i)
{
// Pick up window elements
float window[5];
for (int j = 0; j < 5; ++j)
window[j] = signal[i - 2 + j];
// Order elements (only half of them)
for (int j = 0; j < 3; ++j)
{
// Find position of minimum element
int min = j;
for (int k = j + 1; k < 5; ++k)
if (window[k] < window[min])
min = k;
// Put found minimum element in its place
const float temp = window[j];
window[j] = window[min];
window[min] = temp;
}
// Get result - the middle element
result[i - 2] = window[2];
}
}
int main()
{
return 0;
}
CPU управляет DSP-ядром: устанавливает зна�чения его регистров управления и состояния, формирует входные массивы и размещает их в памяти DSP XYMEM, запускает DSP-ядро:
#include <unistd.h>
#include "risc_runtime/nvcom_01.h"
#include "risc_runtime/debug_printf.h"
#include "risc_runtime/simple_time.h"
#include "risc_runtime/overlay.h"
#include "risc_runtime/init.h"
extern int __dsp_main;
extern int __dsp_MedianFilter;
extern int __dsp_x;
extern int __dsp_y;
float x[200];
float y[200];
float z0[200];
float z1[200];
int xx0;
int seed;
void Initrand ()
{
seed = 74755L; /* constant to long WR */
}
int Rand ()
{
seed = (seed * 1309L + 13849L) & 65535L; /* constants to long WR */
return ((int) seed); /* typecast back to int WR */
}
//
// @description: initialize input vectors with given value
//
void AssignVector(float *in, int length, float value)
{
int i, j;
for (i = 0; i < length; i++)
{
in[i]= value;
}
}
//
// @description: initialize input vectors with some random values
//
void SetupVector(float *in, int length)
{
int i, j;
for (i = 0; i < length; i++)
{
in[i] = 1.0f*Rand();
}
}
//
// @name: CallMedianFilter
// @description: prepare dsp core run median filter function, setups vectors in dsp
// @input int - parameter for send to dsp function
// @output - value, returned by dsp function
//
int CallMedianFilter()
{
// setup initial values for dsp registers from overlay descriptions
int DSP_PC = (unsigned int)&__dsp_MedianFilter;
struct ovl_ctx *ctx = find_overlay_ctx(DSP_PC);
int DSP_NUM = ctx->dsp_info->num;
int QSTR_STOP = ctx->dsp_info->qstr_stop;
// prepare vector for median filter (it must be placed in DSP XYMEM)
//SetupVector((float*) xyram_word_address_to_risc(__dsp_x,
//get_page_size(ctx->dsp_info->page_mode)), 200);
//AssignVector((float*) xyram_word_address_to_risc(__dsp_y,
//get_page_size(ctx->dsp_info->page_mode)), 200, 0.0f);
SetupVector((float*) (&__dsp_x), 200);
AssignVector((float*) (&__dsp_y), 200, 0.0f);
// load program into dsp memory
if(!load_overlay(ctx)) return 0;
// setup dsp registers
DCSR(DSP_NUM) = 0;
SR(DSP_NUM) = 0;
SS(DSP_NUM) = (*ctx).__exit_dsp;
SP(DSP_NUM) = 1;
PC(DSP_NUM)=(DSP_PC - (unsigned int)((*ctx).__text_src) + ((*ctx).__text_offset))>>2;
A7(DSP_NUM)=0x7ffc;
A6(DSP_NUM)=0x7ffc;
// it has no sense in this example, you can send parameter to dsp function via register
// see "calling convention" in clang documentation
R0_L(DSP_NUM) = risc_to_xyram_byte_address((unsigned int)&__dsp_x, get_page_size(ctx->dsp_info
->page_mode));
R1_L(DSP_NUM) = risc_to_xyram_byte_address((unsigned int)&__dsp_y, get_page_size(ctx->dsp_info
->page_mode));
R2_L(DSP_NUM) = 200;
DCSR(DSP_NUM) = 0x4000;
// run dsp
const unsigned qstr_mask = (0xf << (DSP_NUM * 8));
const unsigned stop_mask = (1<<QSTR_STOP);
while(1)
{
unsigned qstr = QSTR_DSP;
if((qstr & qstr_mask) == stop_mask) break;
}
// receive value from dsp
// see "calling convention" in clang documentation
return R0_L(DSP_NUM);
}
main()
{
config_overlay(0,0);
int _i = CallMedianFilter();
while (1) ;
};
Реализация медианного фильтра с использованием DMA-каналов (sample_median_dma)
В этом примере функция MedianFilter вызывается программным прерыванием CPU. DMA-каналы используются для передачи данных между DSP XRAM0 CRAM и обратно. Код для DSP:
#include "DspRuntime.h"
#include <stdlib.h>
float x[200];
float y[200];
float z0[200];
float z1[200];
//
// @description: 1d median filter
// @parameters : signal - input signal
// result - output signal
// N - length of the signal
void MedianFilter(const float* signal, float* result, int N)
{
// Move window through all elements of the signal
for (int i = 2; i < N - 2; ++i)
{
// Pick up window elements
float window[5];
for (int j = 0; j < 5; ++j)
window[j] = signal[i - 2 + j];
// Order elements (only half of them)
for (int j = 0; j < 3; ++j)
{
// Find position of minimum element
int min = j;
for (int k = j + 1; k < 5; ++k)
if (window[k] < window[min])
min = k;
// Put found minimum element in its place
const float temp = window[j];
window[j] = window[min];
window[min] = temp;
}
// Get result - the middle element
result[i - 2] = window[2];
}
}
//
// @description: this function is wrapper to MedianFilter.
// In this example it is called from intterupt which is caused by cpu program interrupt
//
void CallMedianFilter()
{
MedianFilter(x, y, 200);
RequestDMAMemCh(0);
}
//
// @description: PI approximation
// @parameters : startstep -
// endstep -
// step -
float SuperPi(int startstep, int endstep, float step)
{
float x;
float sum = 0.0;
for (; startstep < endstep; startstep++)
{
x = (startstep - 0.5) * step;
sum = sum + 4.0 / (1. + x * x);
if(sum < (2 * (startstep + 1))) exit(-1);
}
sum *= step;
return sum;
}
int main()
{
return 0;
}
Код для CPU:
#include <unistd.h>
#include "risc_runtime/nvcom_01.h"
#include "risc_runtime/debug_printf.h"
#include "risc_runtime/simple_time.h"
#include "risc_runtime/overlay.h"
#include "risc_runtime/init.h"
#include "DspInterrupt.h"
extern int __dsp_SuperPi;
extern int __dsp_x;
extern int __dsp_y;
// interrupt handler function
extern int __dsp_inter_hnlr;
float x[200];
float y[200];
int xx0;
int seed;
void Initrand ()
{
seed = 74755L; /* constant to long WR */
}
int Rand ()
{
seed = (seed * 1309L + 13849L) & 65535L; /* constants to long WR */
return ((int) seed); /* typecast back to int WR */
}
//
// @description: initialize input vectors with given value
//
void AssignVector(float *in, int length, float value)
{
int i, j;
for (i = 0; i < length; i++)
{
in[i]= value;
}
}
//
// @description: initialize input vectors with some random values
//
void SetupVector(float *in, int length)
{
int i, j;
for (i = 0; i < length; i++)
{
in[i] = 1.0f*Rand();
}
}
typedef union _FLINT{
int _i;
float _f;
} FLINT;
Функция CallMedianFilter готовит DSP-ядро для запуска медианного фильтра, устанавливает векторы в DSP, инициализирует обработчик прерываний, отправляет программное прерывание в DSP, инициализирует DMA-передачу между DSP XRAM0 и CRAM.
//
// @name: CallMedianFilter
// @description:
//prepare dsp core run median filter function, setups vectors in dsp,
//initialize dsp interrupt handler, send program interrupt to dsp,
//initialize DMAMemChannle0 data transfer between DSP XRAM0 and CRAM
//
// @input
// @output - value, returned by dsp function
//
int CallMedianFilter()
{
FLINT val;
// setup initial values for dsp registers from overlay descriptions
// int DSP_PC = (unsigned int)&__dsp_MedianFilter;
int DSP_PC = (unsigned int)&__dsp_SuperPi;
struct ovl_ctx *ctx = find_overlay_ctx(DSP_PC);
int DSP_NUM = ctx->dsp_info->num;
int QSTR_STOP = ctx->dsp_info->qstr_stop;
R0_L(DSP_NUM) = 1;
R1_L(DSP_NUM) = 50000;
val._f = 1/50000.0f;
R2_L(DSP_NUM) = val._i;
// load program into dsp memory
if(!load_overlay(ctx)) return 0;
// setup dsp registers to initalize DSP interrupts and DSP interrupt
// handler
// setup DSP interrupt handler function
IVAR(DSP_NUM) = ((unsigned int)&__dsp_inter_hnlr - (unsigned int)((*ctx).__text_src) + ((*ctx)
.__text_offset))>>2; // __dsp_inter_hnlr;
// enable DSP interrupt handling from risc
IMASKR(DSP_NUM) = 0x9f00000f;
// setup dsp registers to call function
DCSR(DSP_NUM) = 0;
SR(DSP_NUM) = 0;
SS(DSP_NUM) = (*ctx).__exit_dsp;
SP(DSP_NUM) = 1;
PC(DSP_NUM)=(DSP_PC - (unsigned int)((*ctx).__text_src) + ((*ctx).__text_offset))>>2;
A7(DSP_NUM)=0x7ffc;
A6(DSP_NUM)=0x7ffc;
const unsigned qstr_mask = (0xf << (DSP_NUM * 8));
const unsigned stop_mask = (1<<QSTR_STOP);
// configure DMAMemCh0, prepare DMA send of 200 32-bit values numbers between XRAM -> CRAM
ConfigureMemCh(0, (unsigned int*)&__dsp_y, (unsigned int*)y, 200*sizeof(float));
// configure DMAMemCh1, prepare DMA send of 200 32-bit values numbers between CRAM -> XRAM
ConfigureMemChDSP(1, (unsigned int*)&x, (unsigned int*)&__dsp_x, 200*sizeof(float));
// run dsp
DCSR(DSP_NUM) = 0x4000;
// run dma, send interrupt to dsp from risc
StartMemCh(1);
WaitMemChRun(1);
// wait DMA transfer (XRAM->CRAM) is completed
WaitMemChRun(0);
// wait dsp stops
while(1)
{
unsigned qstr = QSTR_DSP;
if((qstr & qstr_mask) == stop_mask) break;
}
// receive value from dsp
// see "calling convention" in clang documentation
return R0_L(DSP_NUM);
}
main()
{
config_overlay(0,0);
// calls DSP, sends data array to DSP via DMAMemChannel1 (and intterupts
// DSP after DMA transfer), receives data array from DSP via DMAMemChannel0
// prepare vector for median filter (it must be placed in DSP XYMEM)
SetupVector(x, 200);
AssignVector((float*) y, 200, 0.0f);
AssignVector((float*) (&__dsp_y), 200, 0.0f);
FLINT dsp_ret;
dsp_ret._i = CallMedianFilter();
while (1) ;
};
Реализация медианного фильтра с использованием DMA и прерываний (sample_median_interrupt)
Код для DSP:
// Dsp program sample 1d-median filter
#include <stdlib.h>
float x[200];
float y[200];
float z0[200];
float z1[200];
//
// @description: 1d median filter
// @parameters : signal - input signal
// result - output signal
// N - length of the signal
void MedianFilter(const float* signal, float* result, int N)
{
// Move window through all elements of the signal
for (int i = 2; i < N - 2; ++i)
{
// Pick up window elements
float window[5];
for (int j = 0; j < 5; ++j)
window[j] = signal[i - 2 + j];
// Order elements (only half of them)
for (int j = 0; j < 3; ++j)
{
// Find position of minimum element
int min = j;
for (int k = j + 1; k < 5; ++k)
if (window[k] < window[min])
min = k;
// Put found minimum element in its place
const float temp = window[j];
window[j] = window[min];
window[min] = temp;
}
// Get result - the middle element
result[i - 2] = window[2];
}
}
void CallMedianFilter()
{
MedianFilter(x, y, 200);
}
//
// @description: PI approximation
// @parameters : startstep -
// endstep -
// step -
float SuperPi(int startstep, int endstep, float step)
{
float x;
float sum = 0.0;
for (; startstep < endstep; startstep++)
{
x = (startstep - 0.5) * step;
sum = sum + 4.0 / (1. + x * x);
if(sum < (2 * (startstep + 1))) exit(-1);
}
sum *= step;
return sum;
}
int main()
{
return 0;
}
Код обработчика прерываний, исполняется DSP-ядром (interrupts.s):
.text
; don't change, size of context with clang
; .define CONTEXT_SIZE 0x82
; ************************************ _inter_hnlr ********************
; description: DSP interrupt handler, its address must be written in
; IVAR register
;
; *********************************************************************
.globl _inter_hnlr
.align 4
.type _inter_hnlr,@function
_inter_hnlr:
; --------------------- save context -----------------------------
; !!! do not edit till 'interrupt handler code' block
;
nop
nop
nop
nop
;Read, Save, Reset irqr
move A0.l, R31.l
move _IRQR_DUMP, A0.l
move irqr.l, R30.l
move R30.l, (A0)
move 0, irqr.l
move _TASK_CONTEXT_PTR, A0.l
move (A0), R30.l
move R30.l, A0.l
b _save_regs
nop
_end_save:
; --------------------- interrupt handler code ----------------------
; add interrupt cause analysis here, function call to be execukted in
; interrupt handler and so on accordingly to specific of application
;
; cause of interrupt is in memory, address _IRQR_DUMP
; --------------------------------------------------------------------
; call "interrupt" function
; place your own function name here
js _CallMedianFilter
nop
; --------------------- restore context -----------------------------
; do not edit this block of interrupt handler
;
move _TASK_CONTEXT_PTR, A0.l
move (A0), R30.l
move R30.l, A0.l
b _restore_regs
nop
_end_restore:
nop
nop
nop
rti
nop
; ************************************ _save_regs *********************
; description: it saves context in interrupt handler
; inputs: a0 - contains address of memory to store problem context
;
; ********************************************************************
_save_regs:
;
;Stack pointer
move A6.l, R30.l
move R30.l, (A0)+ ;A6 [0]
;Frame pointer
move A7.l, R30.l
move R30.l, (A0)+ ;A7 [1]
move m0, R30.s
move m1, R31.s
move R30.l, (A0)+ ;m0 m1 [2]
move m2, R30.s
move m3, R31.s
move R30.l, (A0)+ ;m2 m3 [3]
move m4, R30.s
move m5, R31.s
move R30.l, (A0)+ ;m4 m5 [4]
move m6, R30.s
move m7, R31.s
move R30.l, (A0)+ ;m6 m7 [5]
move mt, R30.s
move dt, R31.s
move R30.l, (A0)+ ;MT DT [6]
move sr, R30.s
move ccr, R31.s
move R30.l, (A0)+ ;SR CCR [7]
move pdnr, R30.s
move it, R31.s
move R30.l, (A0)+ ;PDNR IT [8]
move sfr.l, R30.l
move R30.l, (A0)+ ;SFR [9]
move R31.l, R30.l
move R30.l, (A0)+ ;A0 [10]
move A1.l, R30.l
move R30.l, (A0)+ ;A1 [11]
move A2.l, R30.l
move R30.l, (A0)+ ;A2 [12]
move A3.l, R30.l
move R30.l, (A0)+ ;A3 [13]
move A4.l, R30.l
move R30.l, (A0)+ ;A4 [14]
move A5.l, R30.l
move R30.l, (A0)+ ;A5 [15]
move i0, R30.s
move i1, R31.s
move R30.l, (A0)+ ;i0 i1 [16]
move i2, R30.s
move i3, R31.s
move R30.l, (A0)+ ;i2 i3 [17]
move i4, R30.s
move i5, R31.s
move R30.l, (A0)+ ;i4 i5 [18]
move i6, R30.s
move i7, R31.s
move R30.l, (A0)+ ;i6 i7 [19]
move AC0.l, R30.l
move R30.l, (A0)+ ;AC0 [20]
move AC1.l, R30.l
move R30.l, (A0)+ ;AC1 [21]
move AC2.l, R30.l
move R30.l, (A0)+ ;AC2 [22]
move AC3.l, R30.l
move R30.l, (A0)+ ;AC3 [23]
move AC4.l, R30.l
move R30.l, (A0)+ ;AC4 [24]
move AC5.l, R30.l
move R30.l, (A0)+ ;AC5 [25]
move AC6.l, R30.l
move R30.l, (A0)+ ;AC6 [26]
move AC7.l, R30.l
move R30.l, (A0)+ ;AC7 [27]
move AC8.l, R30.l
move R30.l, (A0)+ ;AC8 [28]
move AC9.l, R30.l
move R30.l, (A0)+ ;AC9 [29]
move AC10.l, R30.l
move R30.l, (A0)+ ;AC10 [30]
move AC11.l, R30.l
move R30.l, (A0)+ ;AC11 [31]
move AC12.l, R30.l
move R30.l, (A0)+ ;AC12 [32]
move AC13.l, R30.l
move R30.l, (A0)+ ;AC13 [33]
move AC14.l, R30.l
move R30.l, (A0)+ ;AC14 [34]
move AC15.l, R30.l
move R30.l, (A0)+ ;AC15 [35]
move R0.q, (A0)+ ;R0.q [36-39]
move R2.q, (A0)+ ;R2.q [40-43]
move R4.q, (A0)+ ;R4.q [44-47]
move R6.q, (A0)+ ;R6.q [48-51]
move R8.q, (A0)+ ;R8.q [52-55]
move R10.q, (A0)+ ;R10.q [56-59]
move R12.q, (A0)+ ;R12.q [60-63]
move R14.q, (A0)+ ;R14.q [64-67]
move R16.q, (A0)+ ;R16.q [68-71]
move R18.q, (A0)+ ;R18.q [72-75]
move R20.q, (A0)+ ;R20.q [76-79]
move R22.q, (A0)+ ;R22.q [80-83]
move R24.q, (A0)+ ;R24.q [84-87]
move R26.q, (A0)+ ;R26.q [88-91]
move R28.q, (A0)+ ;R28.q [92-95]
move at.l, R30.l
move R30.l, (A0)+ ;AT [96]
clrl R4.l
clrl R30.l
move sp, R30.s
and 0xF, R30.s
move R30.l, (A0)+
_start_save_ss:
cmp 0x0, R30
b.eq _end_save_ss
nop
dec R30.s, R30.s
move ss, R4.s
move R4.l, (A0)+
b _start_save_ss
nop
_end_save_ss:
move la, R4.s
move lc, R5.s
move R4.l, (A0)+
move sp, R30.s
lsr 0x8, R30.s, R30.s
and 0x7, R30
move R30.l, (A0)+
_start_save_cs:
cmp 0x0, R30
b.eq _end_save_cs
nop
dec R30, R30
move csh, R4.s
move csl, R5.s
move R4.l, (A0)+
b _start_save_cs
nop
_end_save_cs:
b _end_save
nop
; ************************************ _restore_regs *****************
; description: it restores context in interrupt handler
;
; ********************************************************************
_restore_regs:
move A0.l, R4.l
move R4.l, R30.l
addl 0x61, R30.l
move R30.l, A0.l
move (A0), R30.l
andl 0xF, R30.l
cmpl 0x0, R30.l
b.eq _end_restore_ss
nop
move A0.l, R0.l
addl R30.l, R0.l
move R0.l, A0.l
_start_restore_ss:
move (A0)-, R2.l
move R2.s, ss
dec R30, R30
cmp 0x0, R30
b.ne _start_restore_ss
nop
_end_restore_ss:
addl 0x1, R0.l
move R0.l, A0.l
move (A0)+, R30.l
move R30.s, la
move R31.s, lc
move (A0), R30.l
andl 0x7, R30.l
cmpl 0x0, R30.l
b.eq _end_restore_cs
nop
addl R30.l, R0.l
move R0.l, A0.l
_start_restore_cs:
move (A0)-, R2.l
move R2.s, csh
move R3.s, csl
dec R30, R30
cmp 0x0, R30
b.ne _start_restore_cs
nop
_end_restore_cs:
move R4.l, A0.l
;Stack pointer
move (A0)+, R30.l ;A6 [0]
move R30.l, A6.l
;Frame pointer
move (A0)+, R30.l ;A7 [1]
move R30.l, A7.l
move (A0)+, R30.l ;m0 m1 [2]
move R30.s, m0
move R31.s, m1
move (A0)+, R30.l ;m2 m3 [3]
move R30.s, m2
move R31.s, m3
move (A0)+, R30.l ;m4 m5 [4]
move R30.s, m4
move R31.s, m5
move (A0)+, R30.l ;m6 m7 [5]
move R30.s, m6
move R31.s, m7
move (A0)+, R30.l ;MT DT [6]
move R30.s, mt
move R31.s, dt
move (A0)+, R30.l ;SR CCR [7]
move R30.s, sr
move R31.s, ccr
move (A0)+, R30.l ;PDNR IT [8]
move R30.s, pdnr
move R31.s, it
move (A0)+, R30.l ;SFR [9]
move R30.l, sfr.l
move (A0)+, R30.l ;A0 [10]
move R30.l, R31.l
move (A0)+, R30.l ;A1 [11]
move R30.l, A1.l
move (A0)+, R30.l ;A2 [12]
move R30.l, A2.l
move (A0)+, R30.l ;A3 [13]
move R30.l, A3.l
move (A0)+, R30.l ;A4 [14]
move R30.l, A4.l
move (A0)+, R30.l ;A5 [15]
move R30.l, A5.l
move (A0)+, R30.l ;i0 i1 [16]
move R30.s, i0
move R31.s, i1
move (A0)+, R30.l ;i2 i3 [17]
move R30.s, i2
move R31.s, i3
move (A0)+, R30.l ;i4 i5 [18]
move R30.s, i4
move R31.s, i5
move (A0)+, R30.l ;i6 i7 [19]
move R30.s, i6
move R31.s, i7
move (A0)+, R30.l ;AC0 [20]
move R30.l, AC0.l
move (A0)+, R30.l ;AC1 [21]
move R30.l, AC1.l
move (A0)+, R30.l ;AC2 [22]
move R30.l, AC2.l
move (A0)+, R30.l ;AC3 [23]
move R30.l, AC3.l
move (A0)+, R30.l ;AC4 [24]
move R30.l, AC4.l
move (A0)+, R30.l ;AC5 [25]
move R30.l, AC5.l
move (A0)+, R30.l ;AC6 [26]
move R30.l, AC6.l
move (A0)+, R30.l ;AC7 [27]
move R30.l, AC7.l
move (A0)+, R30.l ;AC8 [28]
move R30.l, AC8.l
move (A0)+, R30.l ;AC9 [29]
move R30.l, AC9.l
move (A0)+, R30.l ;AC10 [30]
move R30.l, AC10.l
move (A0)+, R30.l ;AC11 [31]
move R30.l, AC11.l
move (A0)+, R30.l ;AC12 [32]
move R30.l, AC12.l
move (A0)+, R30.l ;AC13 [33]
move R30.l, AC13.l
move (A0)+, R30.l ;AC14 [34]
move R30.l, AC14.l
move (A0)+, R30.l ;AC15 [35]
move R30.l, AC15.l
move (A0)+, R0.q ;R0.q [36-39]
move (A0)+, R2.q ;R2.q [40-43]
move (A0)+, R4.q ;R4.q [44-47]
move (A0)+, R6.q ;R6.q [48-51]
move (A0)+, R8.q ;R8.q [52-55]
move (A0)+, R10.q ;R10.q [56-59]
move (A0)+, R12.q ;R12.q [60-63]
move (A0)+, R14.q ;R14.q [64-67]
move (A0)+, R16.q ;R16.q [68-71]
move (A0)+, R18.q ;R18.q [72-75]
move (A0)+, R20.q ;R20.q [76-79]
move (A0)+, R22.q ;R22.q [80-83]
move (A0)+, R24.q ;R24.q [84-87]
move (A0)+, R26.q ;R26.q [88-91]
move (A0)+, R28.q ;R28.q [92-95]
move (A0)+, R30.l ;AT [96]
move R30.l, at.l
b _end_restore
nop
.data
_IRQR_DUMP: .word 0x0
_TASK_CONTEXT_PTR: .word _TASK_CONTEXT_DATA
; don't change, allocate memory for context with clang
; _TASK_CONTEXT_DATA: .space 0x82
Код для CPU-ядра:
#include <unistd.h>
#include "risc_runtime/nvcom_01.h"
#include "risc_runtime/debug_printf.h"
#include "risc_runtime/simple_time.h"
#include "risc_runtime/overlay.h"
#include "risc_runtime/init.h"
#include "DspInterrupt.h"
extern int __dsp_SuperPi;
extern int __dsp_x;
extern int __dsp_y;
// interrupt handler function
extern int __dsp_inter_hnlr;
float x[200];
float y[200];
float z0[200];
float z1[200];
int xx0;
int seed;
void Initrand ()
{
seed = 74755L; /* constant to long WR */
}
int Rand ()
{
seed = (seed * 1309L + 13849L) & 65535L; /* constants to long WR */
return ((int) seed); /* typecast back to int WR */
}
//
// @description: initialize input vectors with given value
//
void AssignVector(float *in, int length, float value)
{
int i, j;
for (i = 0; i < length; i++)
{
in[i]= value;
}
}
//
// @description: initialize input vectors with some random values
//
void SetupVector(float *in, int length)
{
int i, j;
for (i = 0; i < length; i++)
{
in[i] = 1.0f*Rand();
}
}
// @name: CallMedianFilter
// @description: prepare dsp core run median filter function, setups vectors in dsp
// @input int - parameter for send to dsp function
// @output - value, returned by dsp function
typedef union _FLINT{
int _i;
float _f;
} FLINT;
int CallMedianFilter()
{
FLINT val;
// setup initial values for dsp registers from overlay descriptions
// int DSP_PC = (unsigned int)&__dsp_MedianFilter;
int DSP_PC = (unsigned int)&__dsp_SuperPi;
struct ovl_ctx *ctx = find_overlay_ctx(DSP_PC);
int DSP_NUM = ctx->dsp_info->num;
int QSTR_STOP = ctx->dsp_info->qstr_stop;
R0_L(DSP_NUM) = 1;
R1_L(DSP_NUM) = 100000;
val._f = 1/100000.0f;
R2_L(DSP_NUM) = val._i;
// prepare vector for median filter (it must be placed in DSP XYMEM)
SetupVector((float*) (&__dsp_x), 200);
AssignVector((float*) (&__dsp_y), 200, 0.0f);
// load program into dsp memory
if(!load_overlay(ctx)) return 0;
// setup dsp registers to initalize DSP interrupts and DSP interrupt
// handler
// setup DSP interrupt handler function
IVAR(DSP_NUM) = ((unsigned int)&__dsp_inter_hnlr - (unsigned int)((*ctx).__text_src) + ((*ctx)
.__text_offset))>>2; // __dsp_inter_hnlr;
// enable DSP interrupt handling from risc
IMASKR(DSP_NUM) = 0x9f000000;
// setup dsp registers to call function
DCSR(DSP_NUM) = 0;
SR(DSP_NUM) = 0;
SS(DSP_NUM) = (*ctx).__exit_dsp;
SP(DSP_NUM) = 1;
PC(DSP_NUM)=(DSP_PC - (unsigned int)((*ctx).__text_src) + ((*ctx).__text_offset))>>2;
A7(DSP_NUM)=0x7ffc;
A6(DSP_NUM)=0x7ffc;
const unsigned qstr_mask = (0xf << (DSP_NUM * 8));
const unsigned stop_mask = (1<<QSTR_STOP);
// run dsp
DCSR(DSP_NUM) = 0x4000;
// send interrupt to dsp from risc
IRQR(DSP_NUM) = (1<<31);
// wait dsp stops
while(1)
{
unsigned qstr = QSTR_DSP;
if((qstr & qstr_mask) == stop_mask) break;
}
// receive value from dsp
// see "calling convention" in clang documentation
return R0_L(DSP_NUM);
}
main()
{
FLINT dsp_ret;
dsp_ret._i = 0;
config_overlay(0,0);
dsp_ret._i = CallMedianFilter();
while (1) ;
};
Доступ к внешней памяти (sample_ext_mem)
Пример иллюстрирует загрузку из внешней памяти. DSP (prog.c): Функция int readFromExtMem(int addr) производит загрузку из внешней памяти, входное значение – адрес внешней памяти, выходное –загруженная величина:
int readFromExtMem(int addr)
{
int val = 0;
addr = PADDR(addr);
asm volatile("lsrl 2, %0, r6.l"::"r"(addr));
asm volatile("move r6.l, a5.l":::"a5.l");
asm volatile("move (a5.l), r6.l");
asm volatile("move r6.l, %0":"=r"(val));
return val;
}
Функция writeToExtMem(int addr, int value) загружает значение во внешнюю память, входные значения – адрес и загружаемое значение:
void writeToExtMem(int addr, int value)
{
addr = PADDR(addr);
asm volatile("lsrl 2, %0, r6.l"::"r"(addr));
asm volatile("move r6.l, a5.l":::"a5.l");
asm volatile("move %0, (a5.l)"::"r"(value));
}
void mmemcpy(int* s, int* d, int size)
{
int i = 0;
for(i=0;i<size; i++)
{
*s++ = *d++;
}
}
int main()
{
int val = 0;
writeToExtMem(0x8115A800, 0x12344321);
val = readFromExtMem(0x8115A800);
return (val==0x12344321);
}
CPU (main.c):
#include <unistd.h>
#include "risc_runtime/nvcom_01.h"
#include "risc_runtime/debug_printf.h"
#include "risc_runtime/simple_time.h"
#include "risc_runtime/overlay.h"
#include "risc_runtime/init.h"
extern int __dsp_main;
//
Функция benchmark подготавливает DSP-ядро к работе, входной параметр – номер ядра, выходное значение возвращает DSP.
int benchmark(int i)
{
// setup initial values for dsp registers from overlay descriptions
int DSP_PC = (unsigned int)&__dsp_main;
struct ovl_ctx *ctx = find_overlay_ctx(DSP_PC);
int DSP_NUM = ctx->dsp_info->num;
int QSTR_STOP = ctx->dsp_info->qstr_stop;
// load program into dsp memory
if(!load_overlay(ctx)) return 0;
// setup dsp registers
DCSR(DSP_NUM) = 0;
SR(DSP_NUM) = 0;
SS(DSP_NUM) = (*ctx).__exit_dsp;
SP(DSP_NUM) = 1;
PC(DSP_NUM)=(DSP_PC - (unsigned int)((*ctx).__text_src) + ((*ctx).__text_offset))>>2;
A7(DSP_NUM)=0x7ffc;
A6(DSP_NUM)=0x7ffc;
// it has no sense in this example, you can send parameter to dsp function via register
// see "calling convention" in clang documentation
R0_L(DSP_NUM) = i;
R1_L(DSP_NUM) = 0;
DCSR(DSP_NUM) = 0x4000;
// run dsp
const unsigned qstr_mask = (0xf << (DSP_NUM * 8));
const unsigned stop_mask = (1<<QSTR_STOP);
while(1)
{
unsigned qstr = QSTR_DSP;
if((qstr & qstr_mask) == stop_mask) break;
}
// receive value from dsp
// see "calling convention" in clang documentation
return R0_L(DSP_NUM);
}
main()
{
config_overlay(0,0);
int dsp_ret = benchmark(0);
while (1) ;
};
Библиотека ELcoreSDK
Библиотека ElcoreRuntimeLibrary предназначена для программирования DSP-ядра в составе микросхемы 1892ВМ10Я (NVCom-02T). В библиотеке реализованы функции для управления и программирования DSP-ядра ELcore-30M. Библиотека может быть использована при разработке приложений, использующих возможности DSP-ядра. В состав библиотеки входит:
- модуль для загрузки и запуска программ DSP;
- модуль управления DMA каналами для передачи данных между ядрами DSP, между CPU и DSP;
- модуль управления памятью;
- модуль оверлейной модели;
- модуль управления прерываниями DSP;
- модуль управления прерываниями CPU.
Для микросхемы 1892ВМ10Я библиотека ElcoreRuntimeLibrary состоит из трех частей: для управляющего процессора CPU (MIPS32), для процессора DSP ELcore-30M, общие (могут скомпилированы и исполнятся как на стороне управляющего процессора, так и на стороне DSP). В состав библиотеки для управляющего процессора входят модули, описывающее взаимодействие CPU-DSP, логику работы процессора, входных и выходных портов, каналов передачи данных DMA. В состав библиотеки для DSP входят модули, описывающие логику обработки прерывания на DSP-ядре взаимодействие и синхронизацию двух DSP-ядер в составе кластера. Библиотека находится в составе среды MCStudio3M в директории %MCS3M%/ElcoreSDK. Руководство пользователя – в папке %MCS3M%/ElcoreSDK/ERLib/doc.